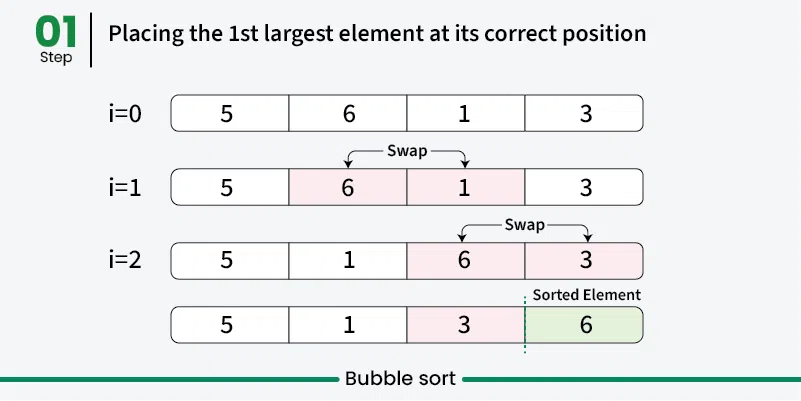
탐색 알고리즘은 말 그대로 어떤 데이터 구조에서 원하는 값이 있는지 찾아내는 알고리즘이다. 선형 탐색 알고리즘가장 간단한 탐색 방법은 선형 탐색이 있다.선형 탐색은 데이터 구조를 처음부터 끝까지 하나씩 살펴보는 것을 말한다.배열이나 리스트같은 선형 데이터 구조에서 사용할 수 있다. 예를 들어 다음과 같은 배열이 있다고 하자.arr = [2, 12, 15, 11, 7, 19, 45] 이 배열에서 7이라는 값을 찾으려고 한다.선형 탐색 알고리즘을 사용하면 배열의 0번 인덱스부터 시작해서 배열의 요소를 하나씩 살펴본다.위 배열을 0번 인덱스부터 살펴보면 2, 12, 15, 11, 7. 다섯번째 요소에서 원하는 값 7을 찾을 수 있다. 이번에는 배열에서 9라는 값을 찾으려고 해보자.9라는 값은 배열에 없기 때문..