배열(Array)
Array는 우리 말로 배열이라고 한다.
배열은 모든 요소를 순서대로 나열한 선형 데이터 구조이다. 배열은 모든 데이터를 메모리의 연속된 위치에 저장한다. 대체로 동일한 데이터 타입의 데이터만을 저장한다.
배열의 가장 큰 특징은, 배열의 첫 번째 요소의 메모리 위치를 안다면 나머지 요소의 위치를 상대적으로 알 수 있다는 것이다. 예를 들어, 어떤 배열의 시작 위치가 0x0010이고 4바이트의 정수형 데이터를 저장하고 있다면 이 배열의 3번째 요소는 0x0010 + 2 * 0x0004 = 0x0018에 있을 것이다.

배열의 인덱스
배열에서 어떤 데이터가 있는 위치를 인덱스라고 한다. 인덱스는 0부터 시작한다. 즉, 배열의 첫번째 데이터의 인덱스는 0이다. 위의 예시에서 배열의 세번째 데이터의 주소를 찾을 때 자료형의 크기에 3이 아니라 2를 곱한 이유가 바로 이것이다.
배열의 인덱스는 많은 데이터를 빠르고 효율적으로 관리할 수 있게 해준다. 예를 들어, 한 학급에 30명의 학생이 있다고 해보자. 우리는 30명의 학생들의 수학 점수의 평균을 구하고싶다.
만약 배열을 사용하지 않고 각 학생들의 데이터를 따로따로 가지고 있다면, 우리는 모든 학생들의 점수를 일일이 더하고, 학생들의 수로 나눠서 평균값을 구해야 할 것이다.
하지만 배열을 사용한다면 배열의 인덱스와 for문을 사용해 모든 학생들의 점수를 순차적으로 계산할 수 있다.
// 배열을 사용하지 않을 때
const Mike = 80;
const Jack = 85;
const Marry = 77;
... and so on
const average = (Mike + Jack + Marry + ... ) / 30;
// 배열을 사용할 때
const students = [80, 85, 77, ... ];
let average = 0;
for(var i = 0; i < 30; i++){
average += students[i];
}
average /= 30;
배열의 크기
고정 크기 배열
우리는 고정 크기 배열의 크기를 변경할 수 없다. 고정 크기 배열은 선언할 때 크기를 명시한다. 우리가 다룰 데이터의 크기를 모르는 경우, 배열을 너무 크게 선언해 메모리가 낭비되거나, 배열이 너무 작아서 모든 데이터를 담을 수 없는 문제가 발생하기도 한다. 이러한 경우 고정 크기 배열은 적절하지 않다.
동적 크기 배열
동적 크기 배열은 런타임중에 사용자의 요구 사항에 따라 크기를 변경할 수 있다. 하지만 배열의 크기를 바꾸는 과정에서 일시적인 연산 부하가 생길 수 있다.
배열의 차원
다차원 배열은 두 개 이상의 차원을 가진 배열이다. 쉽게 말하면 배열의 각 인덱스에 배열을 할당하는 것이다. 이렇게 배열 안에 배열이 있는 구조가 n번 반복되는 구조를 n차원 배열이라고 한다.

배열의 장점
배열은 다른 데이터 구조에 비해 무작위 접근과 캐시 친화성이 뛰어나다.
- 배열은 데이터가 연속된 메모리 위치에 저장되므로 배열의 모든 데이터에 직접적이고 효율적으로 접근할 수 있다.
- 배열은 데이터가 연속된 메모리 위치에 저장되므로 메모리 단편화를 줄일 수 있다.
- 배열은 정수, 부동소수, 문자, 포인터와 같은 간단한 데이터부터 구조체나 객체와 같은 복잡한 데이터까지 광범위한 유형의 데이터를 저장할 수 있다.
배열의 단점
- 대부분의 언어에서 배열은 고정된 크기를 갖는다. 배열의 크기를 변경하려면 새로운 배열을 생성하고 데이터를 복사해야한다. 이는 시간이 많이 걸리고 메모리를 많이 사용한다.
- 큰 배열을 할당하려 하면 메모리에서 충분한 공간을 찾지 못할 수도 있다.
- 배열의 중간에 데이터를 추가하거나 삭제하는 경우에 후속 데이터들을 이동해야 하므로 많은 연산이 필요할 수 있다.
- 배열은 동일한 유형의 데이터만 저장할 수 있으므로 복잡한 데이터 유형에서는 사용이 제한된다.
- 위의 이유로 배열은 연결 리스트나 트리와 같은 구조보다 유연성이 떨어진다.
연결 리스트(Linked List)
연결 리스트는 데이터를 연속된 위치에 저장하지 않고 다음 데이터를 가리키는 포인터를 가진다. 연결 리스트는 연결된 일련의 노드를 가지며, 노드에는 데이터와 다음 노드의 주소를 저장한다.
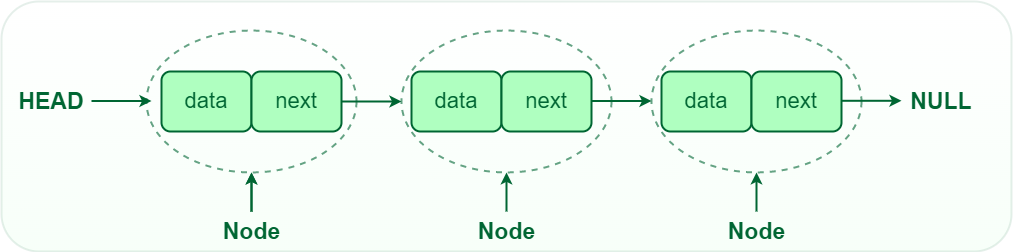
연결 리스트의 헤드와 테일은 각각 연결 리스트의 첫번째 노드와 마지막 노드를 가리킨다. 리스트의 마지막 노드는 null을 가리키며, 이는 리스트의 끝을 의미한다.
단일 연결 리스트(Singly Linked List)
단일 연결 리스트는 각 노드가 자신의 다음 노드를 가리킨다. 가장 단순한 구조의 연결 리스트이다.
이중 연결 리스트(Doubly Linked List)
이중 연결 리스트는 각 노드가 자신의 이전 노드와 다음 노드를 가리킨다.
각 노드가 자신의 이전 노드를 알기 때문에 리스트를 역방향으로 순회할 수 있다. 하지만 각 노드에 추가 포인터가 필요하기 떄문에 단일 연결 리스트보다 메모리 오버헤드가 크다.
원형 연결 리스트(Circular Linked List)
원형 연결 리스트는 마지막 노드와 첫번째 노드가 연결된 형태의 연결 리스트이다. 자기 꼬리를 문 뱀처럼 루프를 형성한다.
원형 연결 리스트는 마지막 노드가 null을 참조하지 않고 head 노드를 참조하기 때문에 null pointer exeption이 발생할 가능성이 줄어든다. 또, 헤드 노드 뿐만 아니라 어느 노드에서 시작하더라고 리스트 전체를 순회할 수 있다.
하지만 명확한 종료 조건을 설정하지 않으면 무한 루프에 빠질 수 있다.
연결 리스트의 장점
- 연결 리스트는 데이터를 효율적으로 삽입하고 삭제할 수 있다. 앞뒤 노드의 포인터만 변경하면 된다.
- 데이터 구조가 간단하기 때문에 스택, 큐 등 다른 자료구조를 구현하는데 활용할 수 있다.
- 다루려는 데이터의 크기를 모르는 경우 공간을 효율적으로 사용할 수 있다.
연결 리스트의 단점
- 연결 리스트의 데이터에 액세스하는 것이 느리다. 헤드 노드로부터 원하는 순서의 데이터에 액세스 하기 위해 노드를 순차적으로 순회해야한다.
- 연결 리스트는 각 노드에 데이터 외에도 다음 노드 혹은 이전 노드에 대한 포인터를 가진다. 이는 추가적인 메모리 오버헤드를 발생시킨다.
- 연결 리스트의 데이터는 메모리에 연속적으로 있지 않기 때문에 캐시 비효율적이다.
배열vs연결 리스트
배열의 장점
- O(1) 시간 안에 임의의 데이터에 접근할 수 있다. 반면 연결 리스트의 경우에는 O(n)의 시간이 걸린다.
- 배열은 연속된 메모리상에 저장되므로 캐시 친화적이다.
- 배열은 연결 리스트와 다르게 포인터나 참조와 같은 오버헤드가 발생하지 않는다.
- 사용이 간단하다.
연결 리스트의 장점
- O(1) 시간 안에 데이터를 삽입하거나 삭제할 수 있다. 반면 배열의 경우에는 O(n)의 시간이 걸린다.
- 큐와 양방향 큐를 구현할 수 있다. 배열은 큐를 구현하기에 효율적이지 않다.
- 데이터의 수를 알 수 없는 경우, 배열에 비해 공간을 효율적으로 사용할 수 있다.
'일기' 카테고리의 다른 글
| 자동 전투 게임 - 로비 UI 만들기 (0) | 2025.03.17 |
|---|---|
| Stack, Queue (0) | 2025.02.26 |
| DFS, BFS (0) | 2025.02.24 |
| 정렬 알고리즘 (0) | 2025.02.19 |
| Big-O (0) | 2025.02.17 |